
If you want to mass-extract the questions and answers shown in Google search results, you can use this tool to split and present tidy data, de-duping as it goes.
Take me to it!
UPDATES:
2022: RETIRED but still available to use for adaptations.
Nov 20th 2019, Updated formulas!
Nov 15th 2019, French version added below! Jump to FR
I’m always tinkering and love building tools (and scalable templates) in Google Sheets. It’s incredibly powerful and I can’t begin to imagine doing my job without it!
This is a simple tool, there are smarter ways to automate this including the extraction but I simply needed a ‘cleaner’ for a few projects and this is what I built. After some friends found it useful too, I thought I’d share it with the wider community. Not my usual form, as I prefer a tool to fully automate the process rather than only solve half the issues but this was all I needed and I hope it’s useful for others too!
I’ve been promising to release some of my other tools for a while now, so I will tidy them up and post some links. Most are really useful, others more for fun and one or two just for the thrill of the challenge. Check back soon.
This Google Sheet tidies mass extraction of ‘People also ask’ shown in Google SERPs
Using one simple Xpath we can mass extract Q&A from Google’s search results. This tool splits and tidies the extraction, with search functionality (by query or domain).
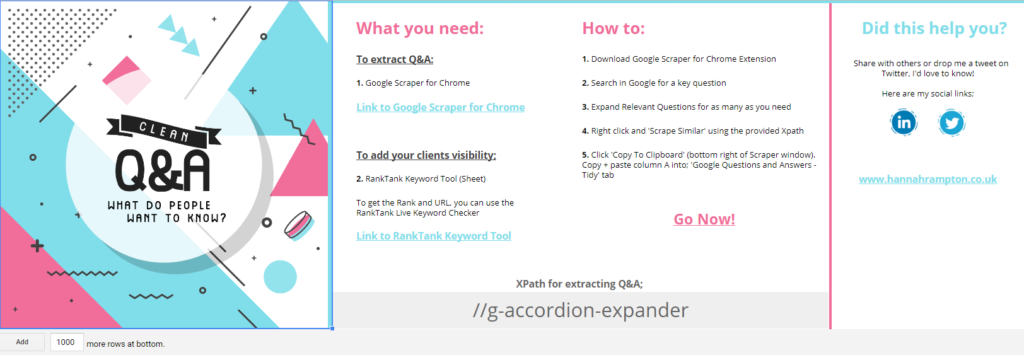
What you need?
- Google Sheet – Google ‘Q&A’ Extraction_v2: https://hanr.link/Google-Q-A
- Scraper for Chrome: https://hanr.link/Chrome-Scraper
![]() French version available here: https://hanr.link/Google-Q-A-FR
French version available here: https://hanr.link/Google-Q-A-FR
(Thanks to Serge for reaching out, this wouldn’t exist otherwise!)
Optional:
- RankTank Live Rank Checker: https://hanr.link/RankTank-KWs
Why?
If you need to research content opportunities or understand what people are asking, this tool can help you extract and analyse the ‘People also Ask’ box in Google Search Results.
There are a number of uses for this, whether you want to pursue the questions themselves, research a competitors inclusions, understand what people are asking to fuel content (on and off-site) or discovery of related topics.
How?
- Go to the Tool (https://hanr.link/Google-Q-A) and go to ‘File’ > ‘Make a Copy’
- Install Chrome Extension ‘Scraper’ (https://hanr.link/Chrome-Scraper)
Once you’re up and running;
- Go to Google and search for a leading question. Aim for something top level and broad to generate better results.
- Click on the relevant questions you want to expand – it’s better working from bottom to top, due to the expansion. Quicker and easier!
3. Continue generating as many questions as you want. I usually pull a few hundred at a time.
Tip: Be mindful which questions you click on, as subsequent questions are generating from this. Some threads stay naturally on track, others divert into related topics quickly – depends what you want!
Now the hardest part is done – Its a copy and paste job from here!
Right click ANY question and select ‘Scrape Similar’. Use the Xpath provided below and ‘Copy to Clipboard’.
//g-accordion-expander
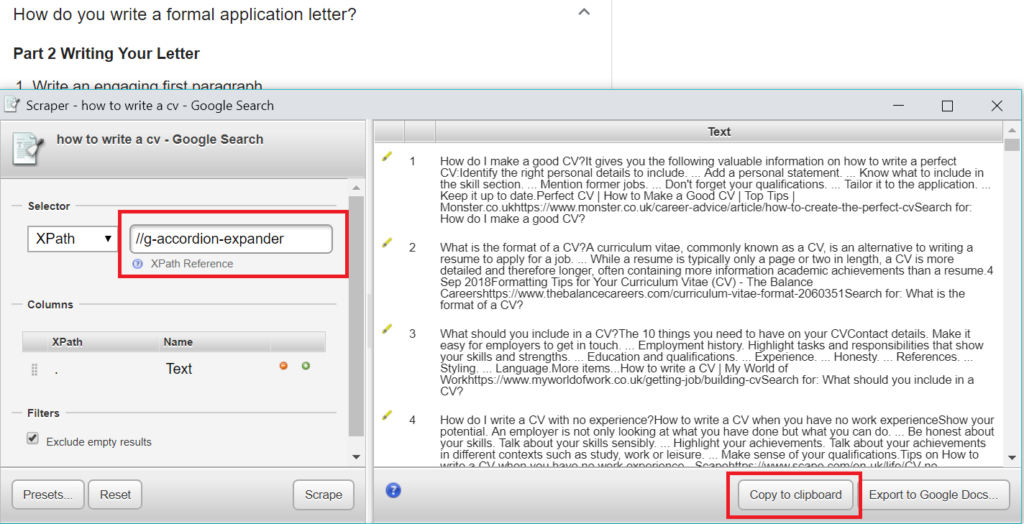
Now just paste into Column A – Voila!
Be sure to explore the other tabs in the sheet, as you can ‘Search by Query’ or ‘Search by Domain’, with clean data output and some extra save functions. Look for the ‘Save or Join Results’ menu. This allows you to:
- Save results in a new tab (easy, quick dumping ground)
- Save results to new spreadsheet. This appends ‘New’ to the end of the filename and adds to your Drive. (See recent files to easily locate)
- Save to joined results. Admittedly, this isn’t flawless and sometimes the script needs a second execution (rare) but this dumps the results into the ‘Joined Results’ tab, adding to the end each time. Helpful when collating a larger data-set!
Enjoy!
I’d love to know if this has helped you! If it did, please share and drop me a tweet.
HanR.
Go to the Tool > https://hanr.link/Google-Q-A (‘Make a Copy’)
Any known issues?
This handles 99% of the extract OK, but around 1 in 100 questions doesn’t correctly extract the URL. This tool is not perfect and wasn’t built to be shared, I just needed it for my own projects and it proved helpful for some others too. I have included a workaround below for those who need it.
This tool still saves a huge amount of time and it’s easy to override the odd error by pasting in the values yourself if a problem question is that crucial. I have added an error handler to show ‘Unable to extract’, so you’ll know when the problem has occurred.
Workaround: Override the odd few errors (~1%) for the domain extraction, or pull these in isolation with an additional Xpath.
Xpath for URLs >
//g-accordion-expander/div/div/div/div/div/div/div/a/div/cite
OR just right-click the URL and ‘Scrape Similar’ like we did above, pasting as values in Column E.
An easy fix would have been to get people to just use these two Xpaths, one for the bulk and the other to pull the domain but this added too many steps for my liking. I would rather keep the one Xpath and wait until I have a free weekend to overcome and ‘patch’ this final issue. As fun as playing in Sheets is, I have some much bigger projects to focus on. In the meantime, I didn’t want to sit on the tool until then as it’s proved so helpful to myself and those around me.
I hope it proves useful all the same